It's been quiet here, but I'm alive! Work is keeping me busy these days, and what's left over is split between building new stuff and writing about it. Writing gets very little.
Work also produced blit.sh, terminal streaming to the browser in a single binary. And for my own productivity, I built zz.surf, a tiling browser for iPad, and moo.pcarrier.com, my web-based coding agent. Combined, they allow a nice workflow on an iPad Pro.
I also redesigned my home page, now a cleaner map of everything I make, and much lighter to load as I moved from iframes to baked screenshots, tailored PragmataPro to only the glyphs I need. And I now carry an NFC keyfob that points to found.as/p, so I'm drinking my own champagne.
This assumes your Odin 3 can boot on EFI thanks to my previous post.
We use Nix flakes to build an image. Everything is defined in flake.nix at pcarrier/sys. The most important part is in hw/odin3.nix as we need a custom kernel today.
Being careful to target the right device, we generate an ISO and write it to the microSD card:
nix build .#nixosConfigurations.odin3iso.config.system.build.isoImage
lsblk # find the SD card device for the next command
sudo dd if=result/iso/nixos-minimal-….iso of=/dev/sd… bs=4M
sync
After powering the device while pressing volume up and volume down at the same time (display goes black after flashing AYN's logo), I could examine the partition tables in my fish shell with:
for lun in (seq 0 5); echo === $lun ===; edl-ng --loader iqoo_13.melf printgpt --lun $lun; end
Made a bunch of improvements to xmit as I've found myself with plenty of time to spare.
Faster site uploads
A few improvements behind the scenes (mostly parallelization) to make sure your sites upload faster than ever.
UI revamp
From the overall page structure and landing page to the admin interface split into more pages, through the docs completely rethought to guide you through the process. The fastest path is a lot shorter thanks to…
Oncle Bob
A simple and lightweight graphical interface to start, build, and launch your site. It's not particularly tied to xmit other than not supporting any other providers yet. You can find it at onclebob.com.
Analytics
Long awaited feature, analytics let you analyze your site's traffic in hits or bytes. You can slice and dice by domain, path, client type, referrer, HTTP status, content type, and response size. Available at xmit.co/analytics.
I've been storing a lot of data somewhat reliably at home, but with my family now entrusting me with their photographs, it was time to up my game.
I'm setting up an HDD NAS for offsite backups. My home storage and media server was already running NixOS, ZFS, sanoid & syncoid (between a zpool of 4 SSDs and a zpool of 8 HDDs and 1 L2ARC SSD partition). A little bit of copy-pasting in my flake repository, nixos-install --flake github:pcarrier/sys#hare, and I'm now mirroring the most critical data to this cheap device over tailscale.
It'll relocate to a family member this week end. At that point I'll have a fast raidz regularly snapshot, with snapshots mirrored to a local raidz and a remote RAID1.
If you're serious about self-hosting and would like a similar setup, I can help you get started. Feel free to reach out!
Imagine a push‑button soldering iron that feeds molten solder right from the tip. Press the handle button and a controlled bead flows exactly where you need it. No separate wire to juggle. You get one‑handed precision, faster work, and cleaner joints, especially in tight spaces or field repairs.
This article is painful to write. Not by nature but by means. I am not using a mouse for a few minutes and my keyboard is physically different for a few days. This is what my desk looks like right now:
Typing this in markdown, opening a preview took me a long time. Empathy for beginners. Reworking my workflows and tooling. Patience. A fair bit of cheating with the mouse, still. And little acceptance. This should work. Accessibility put to an arbitrary test.
I was lukewarm on minimal keyboards after the Planck, but modding a HHKB Pro 2 & slightly switching layouts with a FUN60 Ultra TMR got me back in the mood to try them.
I wrote a post about USB controllers yesterday. I have since ported JerkMonPro to Linux Wayland and… There are inverted between onboard and expansion USB, though great in both cases.
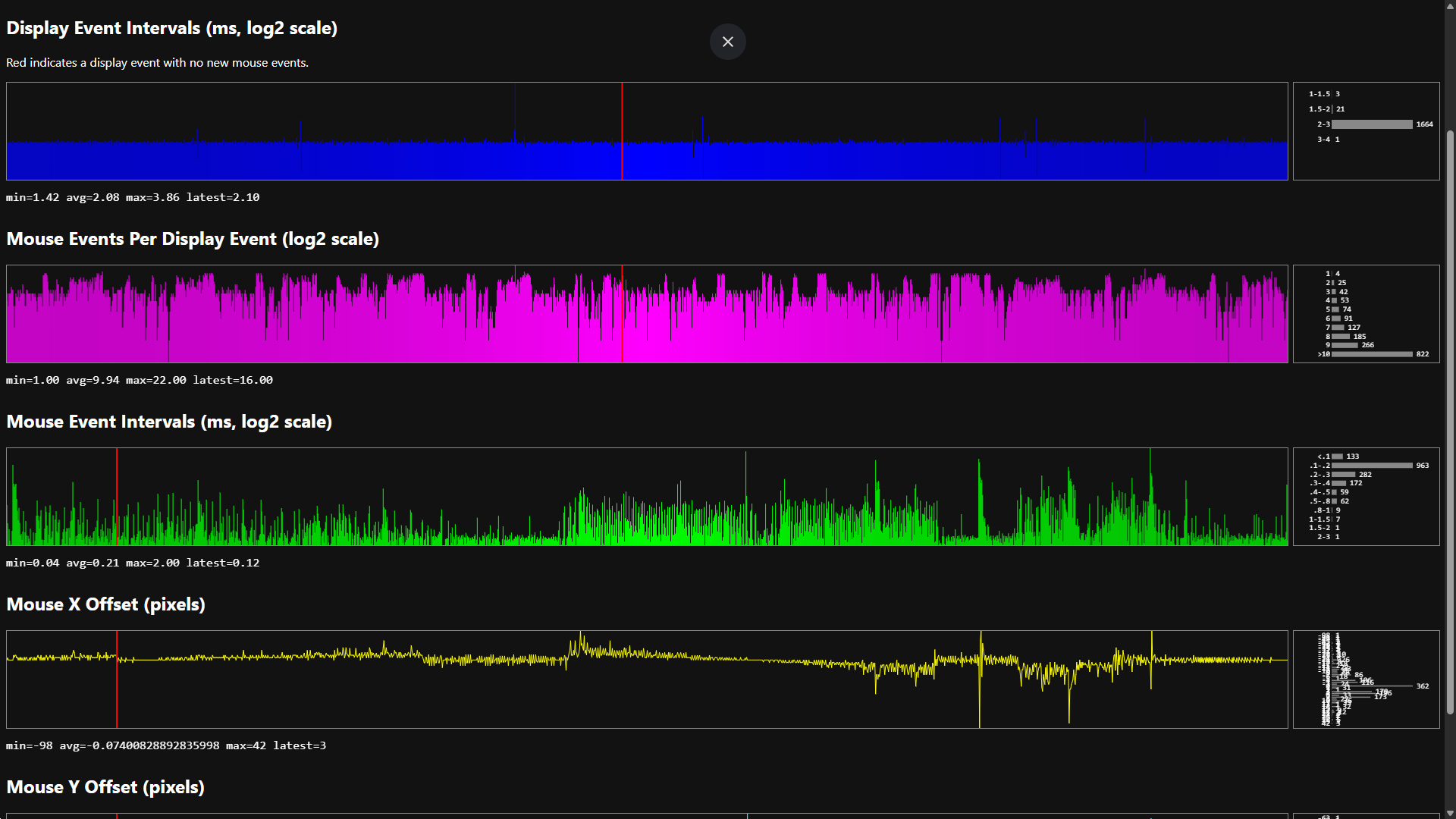
I wrote a post about JerkMonPro yesterday. I have since built a small command-line client to generate latency graphs for extended periods of mouse updates. Here are the first results.
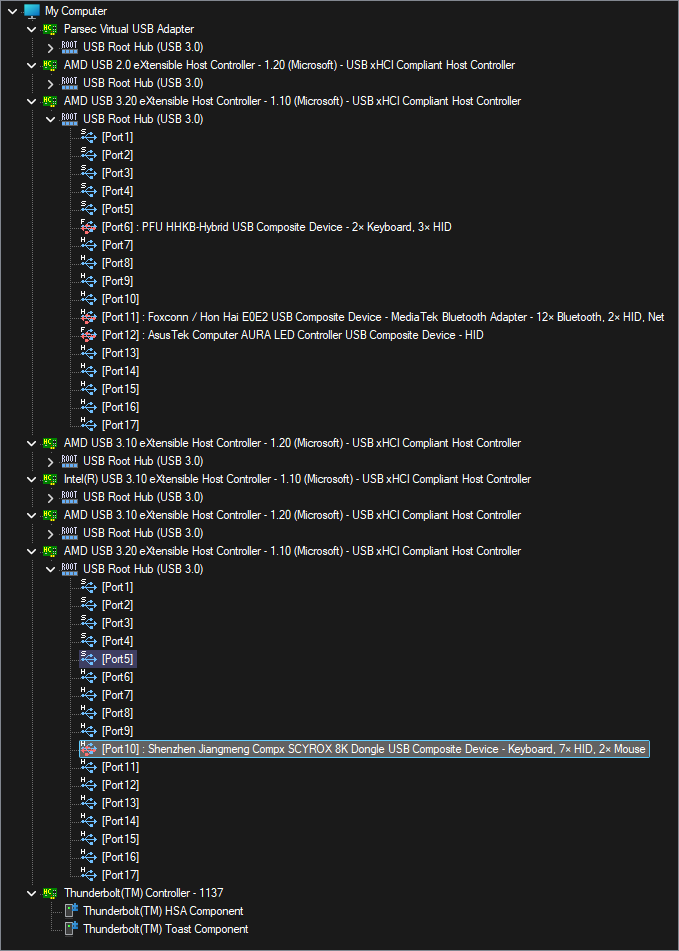
In my quest for the best latency possible, it was suggested to me that I try another USB controller.
I was using a rear port connected to an AMD xHCI controller connected to my CPU, used no other port during tests. The thought that the difference would be measurable amused me. Now equipped with a U3142C board, I've checked. Turns out, it is.
Those measurements were reproduced multiple times, going back and forth between controllers. They were taken seconds apart, only moving the cable between controllers.
Data was captured for 10 seconds of very fast circles each time, using a Razer DeathAdder V4 Pro at 45,000 DPI and 8 kHz polling.
Onboard USB-A (ASUS ProArt X670E-CREATOR WIFI)
The longest intervals get close to 2 milliseconds. Depending on when & how the game engine captures input data, jerk is possible at 500 Hz.
PCI-e expansion card (GLOTRENDS U3142C)
More entries are captured, and that the intervals are a lot more consistent. They peak at about 1 millisecond, or half a frame for a 500 Hz display. Each frame gets a fair chance at observing your mouse movements, jerk should be low.
Adding an otherwise empty hub destroyed performance, seemingly limiting updates to 1 kHz. Enough said.
Bonus 2: Onboard USB-A + 5€ mouse
Even 125 Hz polling shows outliers over 10ms instead of 8 ms. 120 Hz displays miss updates.
2025-07-13 update: oh my Windows…
Cleaned up all unused devices in Device Manager (including ones hidden by default), rebooted, and tried the first rear USB-C port. The results are surprising again:
Onboard USB-A (ASUS ProArt X670E-CREATOR WIFI)
Still not fantastic.
PCI-e expansion card (GLOTRENDS U3142C)
Somehow even better than before. This would be perfectly usable at 1000 Hz. Not sure what's going on.
Onboard USB-C (ASUS ProArt X670E-CREATOR WIFI)
Look at that sample count. Just wow. And now after disabling memory integrity, tweaking my power plan, and rebooting:
This hopefully marks the end of my journey maximizing the performance of my mouse on Microsoft Windows.
I wrote a post about JerkMon a few days ago. I was already a tad obsessed with accurate observations of the behaviour of my pointer. My fixation has only gotten worse since, as I started playing at 480 Hz.
The latest result is a program which captures VSync frame timing, mouse events through buffered raw inputs in Microsoft Windows, and exposes the collected data over WebSocket.
Made JerkMonPro to observe it in great detail. Unlike JerkMon, its portable counterpart, it can afford to feature histograms.
What I've found is that there are at least 3 types of USB3 ports on my workstation:
Some where pauses exceed 10ms every few seconds,
Some where pauses exceed 2ms multiple times per second, and 4ms every few seconds;
Some where pauses never exceed 1ms.
That's now been confirmed with 2 different mice, the same USB cables (tried a few), and the same receiver placement.
For frame-perfect inputs at high refresh rates, this seemingly innocuous choice appears critical.
Edit: Produced some analysis of USB controllers in a new post.
Since upgrading to 240 Hz monitors, I feel a lot better when interacting with my computer, finding I am quite sensitive to latency.
Switching USB ports for my wireless mouse dongle introduced delays of around 10 ms every few seconds. I knew it. I had to prove it.
Unfortunately I couldn't find online tools to study those finer delays. So I made one, found.as/l.
It shows the delay between individual frames rendered by the browser, and between individual pointer movements reported to the webpage. Also reports about the batching of pointer events and their offsets.
To get access to high precision timers, I needed to add to my xmit.toml:
My observation is confirmed. I'll avoid the port. I've also learnt I do benefit from the 8 kHz setting of my mouse, as even at 3200 DPI with fast & smooth motion, some frames still miss a pointer update.
Edit: Published a better version, described in a new post.
Recently acquired an 8BitDo Retro R8 Mouse and I love it. Zero Bluetooth left on my workstation.
It's the first time I invest enough time into setting my pointer up correctly, and the resulting experience is shockingly better for me after just a few hours.
If my mouse is set to 3200 DPI, I want a movement of 1 inch to always translate my pointer 3200 pixels; no less, no more.
What to tweak
There are two parameters in the way of my happiness: acceleration and scale.
Acceleration
I like a flat response curve. That is to say, if I move a certain physical distance, I want the pointer to move by a fixed number of pixels, regardless of the speed at which I move. Makes it a lot easier for me to predict how much to move based on where I am and where I am headed on display, so I don't overshoot or undershoot nearly as much.
Mainstream operating systems, however, offer acceleration by default. macOS doesn't even offer a native way to disable it. The pointer speed is not proportional to the mouse speed. Slow movements move the pointer less than fast ones over the same distance. To my brain, that's breaking the laws of physics.
Scale
The default in both Microsoft Windows and macOS is to scale down: at 3200 DPI, moving an inch moves less than 3200 pixels. I guess most people use higher DPI mice than they'd want, so the software defaults adapted.
My mice and trackballs are configurable, and I want the OS to respect that configuration without interference.
How to tweak
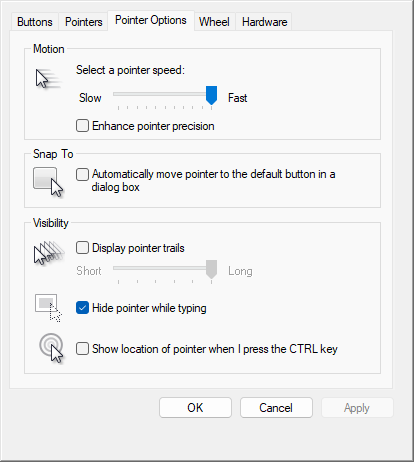
Microsoft Windows
In the Settings app, open Bluetooth & devices, then Mouse, and select Additional mouse settings. In this window, switch to the Pointer options tab, make sure the speed is 6/11 and not to enhance pointer precision.
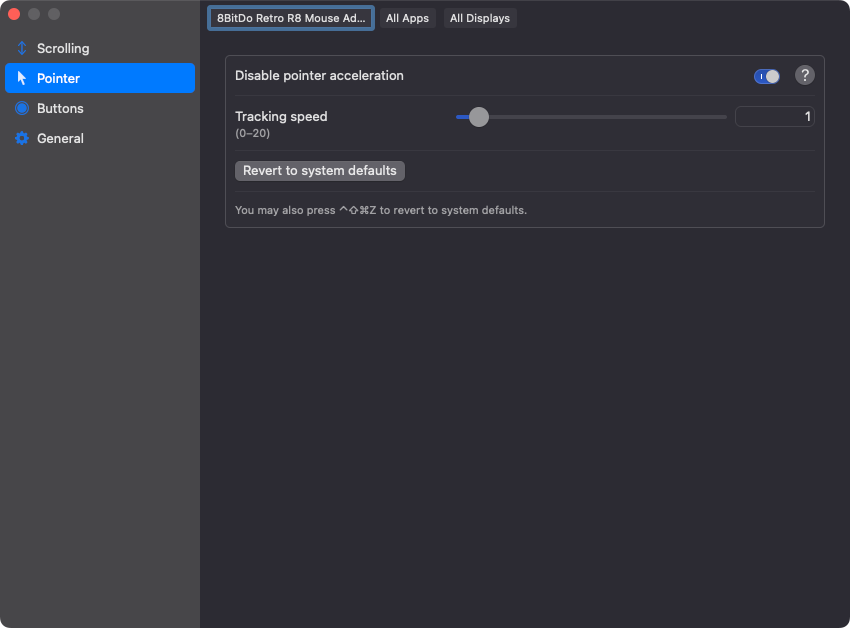
macOS
Too bad it requires third-party software, but LinearMouse.app is perfect. I configure it like so:
Thanks to WSL, there isn't much I miss from my Linux days. The lack of tiling window management was a major drawback though.
That's now solved thanks to GlazeWM. There are alternatives, but it's the best I found in the style of i3 & sway. I figured I'd document how I made it work for me.
As you might already know from my desk setup article, I use a HHKB. There aren't a ton of modifier keys available: Ctrl, left and right Alt, left and right Meta. Ctrl and left Alt are essential for me to leave to applications as they're heavily used there. The right Alt key is already used by WinCompose. The left Meta is useful for Windows shortcuts, I wouldn't want to lose it. This only leaves the right Meta, so I replaced initially replaced alt with rwin in GlazeWM's default config. Unfortunately Windows intercepts a lot of those shortcuts.
I found a solution: using KeyTweak I remapped the right Meta to be a right Ctrl. I now use rctrl as a replacement for alt in GlazeWM and everything runs perfectly. It also works out of the box with my laptop's keyboard, which doesn't have a right Meta but does have a right Ctrl I wasn't using either.
You connect to peers over WebRTC by discovering their address from a list of announcements they volunteer.
If we're on the same network it's highly desirable that eg my laptop would connect to my phone through 192.168.0.123. But 192.168.0.123 is dozens of millions of different machines across different networks, and it'd be inconsiderate to attempt connecting to the wrong one. So how do you announce an address unique to this local network?
Multicast DNS! On all desktop OSes + iOS, all modern browsers announce a randomly generated address like 8daed4b0-14b8-4460-89d0-7139ceefe5d9.local that is easily made discoverable on the local network through mDNS.
This leaves some room for optimization (eg your 10.x.x.x-like corporate network where mDNS won't cross many boundaries), but corporate is happy that their network topology isn't exposed on the Internet, so everybody wins.
I found Android an outlier where browsers don't seem to do this (at least not Chrome on my particular phone from Google). Check "WebRTC addresses" on ident.me to see what your browser does!
I got myself a PBF4 from Intech Studio to control my DAWs & VSTs. An immediate goal was to increase the resolution of knobs and faders to leverage 14-bit CC values (between 0 and 16383) rather than the more traditional 7-bit values (between 0 and 127). When you have access to 12 bits of resolution, it's a shame to let 5 of them go to waste… We'll use 11 bits to avoid noise.
Grid Editor let me share the profile with community members, but I figured a walkthrough could be helpful to folks who want to make similar tweaks.
Without further ado, here's the overall process:
First, select any knob or fader and configure it.
Then, copy the configuration to all other knobs and faders.
Then, store the profile in your device.
Finally, to affect all pages, save the module configuration, switch to each page to load it and store it on-device.
In the locals section, hit Add local variable… and enter val14 with the expression:
math.min(self:potmeter_value()*8,16383)
In the MIDI section, switch to 14 bit MIDI, adopt CC number num+20 (the range starting at 20 is unassigned and is unlikely to collide with other controllers), and controller value val14.
Copying to all pots
You can cmd+c the selected element, then select every other knob and fader one by one hitting cmd+v.
Storing the config
At the top-center of the window, hit Store.
Ready to test! Switch to the MIDI Monitor pane in the bottom-left and play with your pots to see the events sent over the MIDI bus.
Applying to all pages
Switch to the Configuration pane in the top-left, hit +, select PBF4 Module, Next, name your config. Then in the page selector below your module, switch to every page, each time selecting your profile on the left, clicking Load Profile, then Store.
To get literally all modules besides the ones you haven't paid for in VCV Rack 2, head to the plugin page, open the DevTools (cmd+alt+i on Chrome Mac), and in the console, enter the line:
I've wasted a lot of time with connectivity issues between Python and Chromium.
Turns out playwright-python's WebSocket implementation is broken.
Released cdproxy to work around the issue. A Go binary that presents itself as a browser running with --remote-debugging-pipe proxying to a ws:// or wss:// URL chosen through the URL environment variable.
Install with:
GOBIN=/usr/local/bin go install github.com/pcarrier/cdproxy@latest
then replace:
from playwright.async_api import async_playwright
asyncwith async_playwright()as p:
browser =await p.chromium.connect_over_cdp(url)
Clocks jumped back 1 hour last night. Insert rant about societal inertia.
On the subject of time zones, if you're the kind of person who likes to read encyclopediae for fun, tzdata can be a fascinating read.
I hope not to offend with those quotes. Time keeping does evolve through colonialism, conflicts, and politics.
China
[…] People's Republic of China. Yes, they really have only one time zone. […] It seems that Uyghurs in Ürümqi has been using Xinjiang since at least the 1960's. I know of one Han, now over 50, who grew up in the surrounding countryside and used Xinjiang time as a child.
Japan
[…] From Paul Eggert (2020-01-19): Starting in the 7th century, Japan generally followed an ancient Chinese timekeeping system that divided night and day into six hours each, with hour length depending on season. In 1873 the government started requiring the use of a Western style 24-hour clock.
Mongolia
Shanks & Pottenger say that Mongolia has three time zones, but The USNO (1995-12-21) and the CIA map Standard Time Zones of the World (2005-03) both say that it has just one. […] From Heitor David Pinto (2024-06-23): Sources about time zones in Mongolia seem to list one of two conflicting configurations. The first configuration, mentioned in a comment to the TZ database in 1999, citing a Mongolian government website, lists the provinces of Bayan-Ölgii, Khovd and Uvs in UTC+7, and the rest of the country in UTC+8. The second configuration, mentioned in a comment to the database in 2001, lists Bayan-Ölgii, Khovd, Uvs, Govi-Altai and Zavkhan in UTC+7, Dornod and Sükhbaatar in UTC+9, and the rest of the country in UTC+8.
Palestine
[…] To summarize, the table should probably look something like that:
I'm still missing a way to simulate a middle click with left and right buttons. Thought I had it with BetterTouchTool but a left click still triggers as well:
If anybody knows a solution, please contact me! Though to be fair, I don't really need a middle button. I guess a delay would have to be introduced on normal left and right clicks, and I'd rather not.
Nintendo doesn't produce Wiimotes anymore. They're unnecessarily bulky for my needs anyway.
Logitech Spotlight is over 110€ here. For a BLE clicker with an accelerometer and gyroscope!?
Ordered Apple's 69€ answer to the problem of controlling my computer from my couch.
Apple's ecosystem appears to provide software for all my needs, and hopefully that won't break with macOS releases (looking at an Elgato capture device and a Brother scanner now stuck in my closet).
I love controllers. It's hard not to take one of each out for a bigger showcase.
They all make some sort of sense to me, with one exception. Can you spot the outlier?
Maybe I would need to spend more time with it, but after a few hours I don't understand how this left the lab.
I can't picture how 2 touch surfaces are even supposed to be used, neither with existing nor potential games.
I don't think they justify missing a D-pad, and the extremely common left joystick + buttons combination is cramped, with the buttons angled wrong for their low position.
Even as I've grown into a full-fledged adult, I find modern handhelds rather big.
Switch Lite, in light gray, barely fits case in my pocket. Steam Deck, in dark gray, requires a fair bit of bag space.
As much as I appreciate the option of accessing many of my Steam games on the go, I carry the Switch Lite more than the Steam Deck.
I hope the trend reverts back. New 3DS XL, in red, already feels rather big in a pocket.
Retro gamers have plenty of options, some clearly too small for my hands. The Analogue Pocket, on the right below, feels a bit cramped after a long session of Tetris.
mpv, fork of mplayer2, fork of MPlayer, is a fantastic media player.
I just discovered by accident that it binds ga and gs to switch audio track and subtitles interactively. What a game changer for me! Good opportunity to point to the default key bindings.
I cannot resist sharing my config, which requires brew install molten-vk on Mac, and is ready for SmoothVideo.
When web agents wonder what to do on a page, the action space typically includes clicking on page elements listening for such events (links, buttons, etc.).
One way to expose those actions to models is to overlay labels on a screenshot of the page. Vimium offers this on the f key:
Overlays are not a great solution though, because they clutter the image, hiding parts of those elements and their neighborhood. It is possible to send screenshots with and without the overlays, but this drops information density, increasing computational costs.
We can also pass image coordinates in text. Models might evolve to understand them well, but as far as I understand, none does today.
The alternative approach I'm suggesting today would be to support extra channels besides the usual red, green, blue, sometimes alpha. This approach is already used on iOS to store depth maps. Here, we'd use them to introduce labels and other visual elements in the image purely additively. I propose calling those “X-ray channels”.
Unfortunately, no vision or multimodal model supports more than RGB images today. I hope RGB(A)X becomes a thing.
When implementing a toy programming runtime, I tried to implement my “language” as a stack of simple layers.
Today, I'd like to describe the bottom of the stack, Barely Even Structured Text or BEST.
Intended as a lightweight (but not strictly minimal) layer, its design can be summarized in a few choices:
Only produce a sequence, no structure yet as it can be built on top (token stream not abstract syntax tree);
2 types of tokens: strings and symbols, nothing more (specialization is made atop);
Allow for arbitrary bytes everywhere in both, including invalid UTF-8;
Quoting is exposed to upper layers, escaping is not;
Keep it simple yet allow as short a representation as possible;
Follow established conventions otherwise.
Here is the full description:
Spaces are separators outside of double quotes and escape sequences.
Strings are prefixed by ' or delimited by ".
The rest is symbols. They can be prefixed by \', or delimited by \" and ".
Quoting is preserved by parsers and printers, and meaningful in some circumstances (eg in STOR, [ starts a vector but \'[ does not).
\ can be used to escape:
' single quote
" double quote
space
\ backslash
n newline
r carriage return
t tab
f form feed
v vertical tab
b backspace
[0-9A-F][0-9A-F] arbitrary byte in hex
u[0-9A-F][0-9A-F][0-9A-F][0-9A-F] unicode code point in hex (represented in UTF-8)
For example, in:
A 'world \'of "dew"
A and of are symbols, the latter single-quoted. world and dew are strings, the latter double-quoted.
Here are 3 strings:
'A\ single\ string
"On each line"
"This one\nis two lines"
Single-quoted strings end before any unescaped space, whereas double-quoted strings only end before an unescaped double-quote, so this is a fine string too:
"A direct line
break works, so do
escaped quotes like \"!"
Simple Textual Object Representation (STOR), pretty much a textual CBOR with explicitly sized integers;
FORM Open Representation Model (FORM), an object model consisting of STOR with cycles;
STORM, the STOR Machine, a virtual machine implementing a concatenative model through a data deque, a context deque, and a stream deque, all containing references to FORM values;
STORK, the STOR Kernel, a document fed into the machine at startup to initialize its context stack with a base vocabulary for its primitives and commonplace constructs.
\x9E appears because U+009E is the non-printable Private Message.
Everything works out great for latin languages as Unicode codepoints 0x80-0xFF are the Latin-1 Supplement block.
What of encoding characters outside the first 2 blocks then, given btoa is the reciprocal of atob?
>btoa('π')
Uncaught InvalidCharacterError: Failed to execute 'btoa' on 'Window': The string to be encoded contains characters outside of the Latin1 range.
I found this surprising. My intuition would have been that btoa works with arbitrary strings.
If and when armor64 gets a web implementation, I hope it offers UTF-8 encoding for JS strings, and only exposes the equivalent of btoa on Uint8Array, atob to Uint8Array.
rabbit, the NAS+media server+… described in my desk setup post, has been running out of storage space. A 4TB NVMe SSD hosts the operating system and a big cache for the zfs pool, a raidz on 4×8TB of SATA SSD storage attached through the ThunderBay 4 mini.
I figure, given its growth rate keeps increasing, that I should invest in a solution that'll remain viable for many years.
So I'm adding a raidz of 8×18TB SATA HDDs to the pool, attached through the ThunderBay 8.
The difference in size between 4×2.5” and 8×3.5” is a bit more intimidating than I expected. I relocated rabbit to the corner next to my desk, freeing some space on it.
That's 126TB of usable storage added to the 24TB I already have, for a nifty total of 150TB or 136TiB.
All this to announce: time to set up good offsite backup solutions for friends and family!
Alfred has had competition, but it remains my launcher of choice.
Out of its many features, one stands out as a huge boost to my productivity and comfort using computers: the clipboard history.
I've tried clipboard history apps on Windows and Linux, but Alfred's design is miles ahead.
It keeps up to months of history. It automatically ignores entries from password management apps. One global shortcut to search. One keypress to insert.
While for me, tiling window managers are the “killer app” for Linux, Alfred is the “killer app” for Mac.
After yesterday's post turned from design doc to a complete implementation including features initially planned for further iterations, I'm going to keep it short today.
Proud owner of a Sony XDR-S61D, I've been enjoying DAB+ radio for a few months now.
It's a lovely experience:
A wider range of stations than FM ever offered here. I listen almost exclusively to FIP which isn't available on FM in Grenoble.
The benefits of reliable digital audio. No tuning, zero static, no audible defects through a small cheap speaker.
Only complaints about the Sony XDR-S61D:
The wake-up timer only works on DC;
Switching from DC to batteries and vice-versa turns it off;
I suspect a lot of static sites want a single dynamic feature: submitting a form to an E-mail address.
I dove into building a service to make that easy, only to realize that it would be a lot easier and elegant to add it directly to my free static hosting platform, xmit.co.
Here is today's design; I welcome feedback and suggestions.
From: "John Doe" <john.doe.gmail.com@forms.xmit.co>
Reply-To: "John Doe" <john.doe@gmail.com>
Subject: [nothing.pcarrier.com] Hello
---
domain = 'personal'
---
How are you?
enctype is only required for file uploads, and all fields are optional. If I POST nothing (curl -d '' https://nothing.pcarrier.com/contact), I receive:
From: "nothing.pcarrier.com" <noreply@forms.xmit.co>
Reply-To: "nothing.pcarrier.com" <noreply@forms.xmit.co>
Subject: [nothing.pcarrier.com] Form submission
then is a URL to redirect to after the form is submitted. When absent, we serve whatever resource is at the requested URL.
I can't quite think of anything important missing in this design; can you? Are there other such small features you'd like to receive from your static hosting provider? I appreciate all feedback!
Been dealing with CAPTCHAs at work, and wow are they stupid.
Companies like CAPSOLVER are solving them faster than one can say “I'm not a robot” for dirt cheap.
So why don't we cut the middle person, the waste of time and energy on both sides of the equation, and offer micropayments as an alternative for the 99%? I'd gladly throw a fraction of a cent at websites to avoid the hassle. Heck, even 1¢ to save 10s of my time costs only $3.6/hour… What a bargain!
And once we have micropayments as alternatives to inferior user experiences, I'll gladly remove ads through bilateral financial agreements rather than undesired ad blockers.
I don't understand what stands in the way. Surely something does. The incentives are there for a microtransaction processing company to take its commission, for consumers to save time for what would be a nominal fee, and for the sites to fight bots through monetization… Win-win-win.
Why haven't Mozilla and Apple integrated a solution in their browsers yet? It truly seems like a no-brainer.
I barely play any wind instruments. That is to say, I can play a couple of tunes poorly on the saxophone, and couple more on the tin whistle (Irish whistle).
A real beginner. In passing, I'd love a tool I can provide with appropriate sheet music to get it back annotated with tabs (fingerings and tonguings).
Yet despite barely knowing how to play anything, I couldn't resist a few purchases.
Pictured here:
In big, a Yamaha Alto Saxophone, the YAS280;
In medium and black, A Yamaha Digital Saxophone, the YDS120;
Clarke tin whistles in C (Black) and D (Black and Sweetone);
It's a lot pricier than the other tin whistles, but it's immediately clear why, and remains much cheaper than an entry-level saxophone.
It looks and feels premium in every way. As a beginner, I love how much easier it is to play on the Wild. Its tone sounds a lot more clear yet consistent (one might say forgiving) to me.
Started a new project last night: offrecord.ca, a private chat service.
Not much to say about it. Needed off-the-record communication one day, built the simplest solution offering privacy and confidentiality. Usage is trivial: pick a channel name (we offer random ones, with 64 bits of entropy), share it as you want (we offer a QR code and native sharing UI), chat away.
Messages and their authors' pseudonyms are encrypted with a TweetNaCl keypair derived from the channel name, whose public key is used as the channel identifier with the service. The service keeps the last 10 messages and their timestamps only in memory and unless the channel is wiped. A presence counter per channel could reveal somebody dropped in unexpected. No IP or effective identifier is ever logged. I track which user agents load the site's codebase, but not where they connect; user agents do not identify individuals.
I started prototyping yas through its website, with the idea of making a small, fast, and cross-platform execution environment for scripts exposed online.
I'd like it to come bundled with a few libraries to make it useful:
A smart, caching HTTP client, also used to fetch scripts and their dependencies;
System bindings for processes and filesystems;
Archive manipulation and extraction (tarballs compressed with gzip or xz, zip, 7zip at a minimum).
Unfortunately an abundance of questions and tradeoffs demotivates me.
Scripting what? Do I want to invest mostly in configuration management, software installation, notably wrapping other runtimes to simplify tools' deployment and execution?
Should the installation modify PATH automatically? Are there elegant solutions for this? I can manipulate the registry on Windows, but what about Mac and Linux? Should I just focus on configuring the shell that invoked the installer?
Should the binary self-update, if so what does that require on each platform?
Should I cut scope down by forgoing a scripting runtime, focus on a descriptive format for deploying and running other tools?
What should be the host language? For lua and quickjs, I tried putting together a bunch of C libraries, which took a really long time (partly because of cross-compilation) and left me with a host of issues. Go would be a breeze with starlark-go, but binaries quickly get very large.
If anybody feels inclined to participate, that could give me a perspective on what's wanted and the push I need to move forward. I'm not necessarily looking for a team, but I'd love to see ideas bouncing around. I made a Discord channel.
At €199 for desktop and €199 for web, I'm glad I purchased it for both.
It powers most pages on my main website and formic.id, my terminal, IDEs and editors, browsers, most apps on Linux, my business cards, my overgrown deck of cards. Really, I put it everywhere I think it fits. And I tend to think it fits everywhere, except lightweight websites as it takes a few MBs.
A few years back, I had written a simple page that made most browsers sluggish, folks. It was intended as a benchmark, but I was still surprised at how hard some took it.
I can't exactly recall which performed how, but initial load and reflow on window resizing could take many seconds. Today, none of the 3 engines in widepread use (Safari's WebKit, Firefox's Gecko, Chrome's Blink) have any issue with it.
However, I once again find myself bringing Blink to a grinding halt. This time, visiting pages like Mathematics on Wikipedia, with custom CSS, in an 8K window. Sure, it's niche. Nice problem to have, I guess.
Safari, on the other hand, loads and reflows smoothly. Looks great, by the way (besides sans-serif not mapping to my favourite font, PragmataPro):
Tristan Perich pushed chiptune to the limits with his 2010 1-Bit Symphony. The album is stored in a standard crystal case. When a switch is on, a battery powers a microchip which outputs music through a digital pin to a headphone jack. One button to skip tracks, one potentiometer to control volume. I adore the minimalism.
Mine doesn't play “correctly” anymore. I hope its production is unique.
I used a SlimBlade trackball a few years ago. I had given up on it mostly because of its low DPI.
Ordered its successor, the SlimBlade Pro, at the beginning of the week.
It's wireless. DPI is configurable past what I want for my 8K display. Only thing I'm missing is software configurability. In short, I wish it let me:
Click on the bottom buttons together to trigger a middle click;
Click on the top buttons to go backward and forward in browsers;
Hold the top-right button and move the ball around to scroll in all directions (horizontal + vertical).
Only the last point is missing from their solution, KensingtonWorks. Unfortunately, it's entirely broken in Sequoia, so I'm stuck with the default behaviour. Might try to build my own Mac software at some point.Update:Found what I wanted!
That being said, those are only wants, not needs, and the SlimBlade Pro has already replaced the Logitech MX Ergo as my input device of choice.
I go to Twin Labs' Paris office about 2 days every 2 weeks; there it was with me:
Back at home today:
Great opportunity to add to the list of hardware from my desk post with items I take out to compose music:
Early on, my computer exposed timelines through a calendar, 1:1 chat (ICQ, AIM), chatrooms (IRC), E-mail (including my beloved threaded mailing lists). I had desktop notifications for the first three, only on keywords for chatrooms. It already felt overwhelming at times, but manageable.
RSS was a nice addition, and captured most everything else for years.
Already then, I dreamt of unifying those disparate systems into the One App Of Prioritized Events. It was a vague dream, with a lot of complexities I barely understood, and a few wacky ideas I still wish I had pursued. Looking back, it might have a Golden Age of potential.
Today the number of timelines I follow exploded. I started listing them all here, only to quickly give up on the unpleasantness. They've caused a lot of disruptions, which often turn into doomscrolling.
Turning most notifications off, unsubscribing from most everything, avoiding reentry, closing the tab or even logging off when I faltered, blocking through /etc/hosts… Whatever I do, I'm never quite satisfied. I don't want to give up on the value, I just want more control over it, notably a better signal to noise ratio.
Today more than ever, I long for an application unifying all those systems. Lots of features immediately come to mind:
Private, fully persistent archival;
Offline search and retrieval;
Tracking of what has been consumed and skipped;
Bookmarking, tagging, scoring;
Routing of content into my own channels, based on media type, source (which platform, channel, contact), keywords and topics;
Opt-in social sharing of the last 3 points, enabling discovery from my network, weighted by distance and/or trust;
Finely tuned observability: very few mobile or desktop notifications, some unread counters; most channels, I'd open when I feel like it, with no indication that anything is waiting.
Unfortunately the interests of platforms are misaligned with many of those goals. They want as much of my attention as possible, to observe and control my experience. Largely to better sell ads or preferential treatment, directly and not.
I'm lucky enough that I could easily afford to pay for lost ad revenue, but the option often isn't there.
And companies have reasons to avoid interoperability besides the advertisement plague. They want to compete in the marketplace through innovation, evolving their product as often as they want, adding and changing features without the restraints of compatibility with third-party applications. I must also mention silly attempts at preventing redistribution (DRMs 🙄).
When data is unshackled from its presentation, when access is negotiated solely by producers and consumers without the meddling of intermediates, decentralization brings about the commoditization of communication and distribution channels, and enables the rise of more humane products and experiences for communicators, creators, and audiences.
I won't pretend I have a clear vision for what the best products would be in that world. I don't know that I'd be able to build much of what I'm hoping for, should that vision cristalize. But I'm convinced our collective intelligence could achieve greater results than the silos we all too often confine ourselves to.
Who pays for what how, I don't know either. But I'd happily give a lot of my resources, time included, to see meaningful progress in that direction. And should the opportunity arise, I could easily bet I'm far from alone.
It has the benefit of letting you reverse lookup in one go:
> shost -r ident.me
v6.ident.me
v4.ident.me
host, dig and drill all resolve names through their respective DNS implementation.
shost doesn't compete but completes, relying on the system's resolver instead.
So, while a lot less information is available about what happens in DNS, what you get back is what most software uses. For example, .local names are looked up through mDNS/zeroconf if your operating system is configured to do so:
I covered how to install baze and introduced sucyesterday. Today, we're looking at statistik.
If you have a bunch of numbers and want a quick look at their distribution, statistik is the simple command for you.
For example, let's look at how many requests each IP made to ident.me. First, let's look at the first 5 requests of the last hour to confirm we're extracting the data correctly (I censored the results):
We wonder if some IPs make more requests than others, and what the distribution looks like. Let's find out by looking at the first 100,000 requests now, passing them through suc to get the number of requests per IP, then statistik for analysis:
We see here that those 100,000 requests came from 45,157 unique IPs. A bit over 70% of IPs made only 1 request; at least 90% made 3 or fewer requests. The top 1% of IPs made 18 or more requests, with the top IP making 741.
You might not be surprised to learn that statistik's implementation is trivial:
#!/usr/bin/env ruby
s =[]
sum =0ARGF.each_line do|l|
n = l.to_f
s << n
sum += n
end
s = s.sort
cnt = s.length
print "size: #{cnt}\n"
print "sum: #{sum}\n"
print "avg: #{sum/cnt}\n\n"
print "min: #{s.first}\n"[10,20,25,30,40,50,60,70,75,80,90,99].eachdo|p|
print "p#{p}: #{s[s.length*p/100]}\n"end
print "p999: #{s[s.length*999/1000]}\n"
print "p9999: #{s[s.length*9999/10000]}\n"
print "max: #{s.last}\n"
There's tons to be said about macrophotography, and I don't intend to cover much of anything here.
The higher your focal length, the more magnification you get, but the less of the image is in focus.
The more you open up your aperture, the more light gets in, but the less of the image is in focus.
The smaller the object, the more magnification you need, and the more light you need to get in.
Already at half-macro or 1÷2 magnification (on a 36×24mm sensor, capturing a surface of 72×48mm), you'll find that opening at f/4, the depth of field is rather narrow:
Things get wilder at 2.5× ultramacro (on a 36×24mm sensor, capturing a surface of 14.4×9.6mm) and f/4. For an object of relative depth (not very flat in the much narrower plane of focus), a couple of options are available:
Decreasing the aperture until diffraction becomes a problem, usually around f/11 to 1/16. To compensate for the loss of light, brighter environments and/or longer exposure times are required.
Focus stacking: combine many photographs taken with at different focus distances, or distances of the camera to the object (through movement of the camera and lens on a macro rail).
We do the latter here using Helicon Focus. Here are 80 frames shown at 10 frames per second:
And the picture they combine to form:
As magnification keeps increasing, photography gets harder: it requires extensive preparation including cleaning (very poorly done here), and avoiding vibrations through dozens and dozens, sometimes hundreds of frames.
The online version was built around my personal desire for remote play, and to turn my phone into a board at an instant's notice. It's functional for both. But…
It lacks bots. A shame given the game was solved by Guy L. Steele Jr. through a brute force search in 1998 and I have a copy of the solution, which produces an O(1) lookup database of position to outcome given optimal play.
It isn't inviting. I'm sure a lot could be done, and given the elegance of the game itself, it wouldn't be lipstick on a pig.
Physical version: needs distribution?
The original trademark, registration #519087, expired in 2021. I have no problem distributing the game under its original name, and my design is distinct enough.
The stocks for boards, pieces, and bags are living in my bedroom closet. I have yet to print rules, and some assembly is required, but it's otherwise ready.
You can write to preorders@teeko.cc, but I have no concrete plans to distribute it beyond hand-delivering it around me at the moment.
A bit further west from the rest, very much worth the walk. Great selection of premium teas served gongfu, delicious-looking desserts (never tried), a calm atmosphere, laptop-friendly.
Tetris got its post; time to cover my other favourite video game.
N++ is, in my opinion, the best platforming game ever made.
Launched under the Metanet Software umbrella, the third in a series of excellent games by Canadian duo Mare Sheppard and Raigan Burns, it features instant restarts upon failure, great physics, simple and elegant visuals, an addictive soundtrack, no scrolling, and pure determinism.
Once introduced to all the elements that can appear in a level, you can understand each new level through visual inspection before it starts. No surprises. Easy to learn but hard to master. Everybody will find their skills challenged here.
The level editor with online sharing complements thousands of levels of increasing difficulty, separated between solo, co-op and race categories, and only cleared by series of 5.
If you play one platformer in your life, make it N++.
Given how slow my CASIO PB-700 was at plotting graphs, around age 8, my parents upgraded me to the Sharp EL-9400 (manual).
It was a big step up for math, but barely programmable. I wanted a fast BASIC playground.
After a lot of starring in stores and begging, I received the dream machine: the TI-92 Plus (manual). It was a TI-89 in the body of a TI-92. Fantastic machine to code in BASIC and, as I discovered after breaking an arm, take notes in class.
Came with a powerful Symbolic Algebraic System and Cabri Géomètre (a brilliant app to construct geometry). Once I discovered how to transfer files from the Internet onto it, a lot of games followed.
It lasted quite a few years. When it finally gave up, I immediately replaced it with its successor, the TI Voyage 200 (manual), which I've kept to this day.
Smaller form factor but AAA batteries instead of AA, double the flash, a really minor revision.
In my adult life, having lost interest in calculators for anything but quick calculations on the go, and having embraced RPN to the point of implementing a postfix language for fun, I've acquired a HP Prime (manual).
Sadly, I don't care to get past the home screen anymore.
My first computer, or what I remember as such, is older than me. Passed down by my father, it was made by CASIO in Japan in 1983, the year System V launched.
200 × 88 × 23 mm, 4 KB of RAM, 4 lines of 20 characters or 32 lines of 160 pixels, with optional printers, tape, and RAM expansions I never saw.
Mine still works great today. And by great, I mean that plotting sin(x) and cos(x) across the screen in BASIC, highlights of my childhood, still takes mere minutes to complete.
After many years on an ever-growing zsh configuration, I switched to fish a few years ago.
While perfectly satisfied with my setup, I wanted something I could recommend to a beginner. fish's simplicity and modern defaults seem like a much better starting point if eschewing POSIX compatibility.
My configuration hasn't grown much since, but a few quality of life improvements have accumulated, so I figured it is worth sharing.
Installs on Apple Silicon macOS
Let's assume you're starting from scratch and want to adopt all my suggestions. Open Terminal.app and run the following:
$ /bin/bash -c"$(curl-fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
$ /opt/homebrew/bin/brew install aria2 bat delta direnv eza fish fzf keychain mise tig wezterm zoxide
$ chsh -s /opt/homebrew/bin/fish
~/.wezterm.lua
Most likely, you'll need to choose another font on line 3.
Unless, of course, you're interested in purchasing PragmataPro, a most excellent project I use nearly everywhere (eg my main site).
local wezterm = require 'wezterm'local config = wezterm.config_builder()
config.font = wezterm.font 'PragmataPro Liga'
config.font_size =14
config.hide_tab_bar_if_only_one_tab =true
config.native_macos_fullscreen_mode =true
config.pane_focus_follows_mouse =true
config.use_fancy_tab_bar =false
config.window_decorations ='RESIZE'
config.window_padding ={ left =0, right =0, top =0, bottom =0}return config
~/.config/fish/config.fish
I made it so it could be copied anywhere; none of the tools need to be installed, but they will be enabled if they are.
iftype-q /opt/homebrew/bin/brew; /opt/homebrew/bin/brew shellenv |source; end
iftype-q keychain; keychain --eval--quiet--inherit any |source; end
iftype-q direnv; direnv hook fish |source; end
iftype-q fzf; fzf --fish|source; end
iftype-q zoxide; zoxide init fish |source; end
iftype-q mise; mise activate fish |source; end
iftype-q caniuse; caniuse --completion-fish |source; end
The first line enables Homebrew on Apple Silicon macOS.
I don't need to be welcomed and invited to type help every time.
>set-U fish_greeting
~/.ssh/config extracts
I like my keys to be added to the agent automatically on first use, for host keys to be automatically accepted for new hosts, and to minimize bandwidth consumption.
With this configuration in place, git help config should open a page in your browser. I won't describe every detail, but a few essentials.
Only including 2 aliases, ss and sss, as everyone should know how status offers a compact output with -s and -b, and is sped up by -uno to avoid looking at the working tree in large repositories.
You should try tig for a quick view of your repository's history. lazygit does a lot more.
You can and should sign your commits with ssh (unless you prefer PGP).
Sci-fi animation inappropriate for children. Nothing short of my favourite piece of media for adults.
A visual masterpiece backing a captivating story, it will take your breath away.
I strongly recommend going in blind, then watching the Scavengers short included below. That said, teaser & trailer follow in case you need convincing.
Carrying their own roast and that of nearby Chulo, offering a variety of brewing methods and alternative drinks, they're a must-taste for any coffee lover visiting the city.
They also offer a great selection of vegan food, some gluten-free.
I visit almost daily, most often enjoy an oat milk flat white. I'm also partial to their dirty chaï, and would suggest espresso tonics if you're feeling adventurous.
I enjoy using my own domains — though I rent a few too many! One of them, rrier.fr was originally purchased solely so I could use pc@rrier.fr as my E-mail address.
Naturally, I wanted to also be known as @pc@rrier.fr on the Fediverse, as part of owning my online identity. Unfortunately, this turned out more challenging that I expected. Here are a few approaches I tried and what I learned along the way.
This let people search for @pc@rrier.fr and find an account. Unfortunately, that indirection would be resolved right there and then: they would then see and follow the mastodon.social account. I couldn't move providers smoothly, as the process to relocate an account disappears all previous content.
I wanted more control over where my content is hosted and stored authoritatively. Onto what seemed like the natural solution.
In my opinion, for a single customer, a server requires too much setup and maintenance work, and too many resources. I gave up a few steps into an installation when I realized the amount of memory my VPS would probably need, so I can't say much more.
I looked around, and found what I think is a better solution for my needs:
Setup was a breeze. Everything is lightweight and fast. I have minor complaints, notably lack of edit capability (already on the roadmap), but it's a fantastic piece of software.
It does, however, suffer from what appears to be limitations inherent to the design of the Fediverse:
My instance is federated with over 2000 other instances, but I don't see their content when looking up or following a hashtag. It only finds stuff that already appeared in the timeline of my lone user… Makes following hashtags pointless, something that I found super valuable when I was on a big instance.Edit: Unfortunately not supported by GoToSocial, relays are a solution to this problem. A tad cumbersome (either hashtag-specific and I need to administer their list whenever (un)following hashtags, or extreme overhead). Thanks Fedi Jedi for the tip!
I can't boost or reply to toots of people I don't already follow, unless they were boosted by the accounts my instance follows… Following them doesn't backfill their history on my instance, so the existing toot remains out of reach.Edit: Search the toot by URL in your client to reach it. Not intuitive to me, but simple. Thanks Aaron Parecki for the tip!
I'd love to learn that those issues can be addressed without protocol changes, or that such protocol changes are underway. In the meantime, I've learnt to live with those grievances.Edit: Not a great UX, but everything seems workable in the end.
Here's my desk, where I spend way too much time. Please pardon the total lack of cable management.
Probably the most obvious characteristic is the big display.
At 8K and 65 inches, the Samsung Neo QLED 8K QN900D takes most of the space on my 200×50cm desk. While far from perfect, with a surface equivalent to 4×4K or 16×1080p, it's fantastic for interacting with and keeping an eye on tons of windows at once.
The sound system is a pair of Focal Alpha 80 Evo studio monitors I adore, connected to a Mackie Mix5 mixing table which has caused me a lot of troubles but does the job of mixing the audio from 2 computers at once.
Mostly here and often off, running Linux and Windows 11, dog. The “workstation” yet not involved in my job much, it provides a powerful environment for gaming, streaming, music composition, etc. It sports a 7950X3D, RTX4090, plenty of RAM and storage for my needs.
Always on, headless, rabbit. A fairly low-power Framework mainboard connected over Thunderbolt to 4×8TB of SSD storage in a ThunderBay 4 mini, and the other 2 computers when present. It acts as a NAS, media server, download box, Docker host, and more.
deb http://us.archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
deb http://us.archive.ubuntu.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://us.archive.ubuntu.com/ubuntu/ trusty-backports main restricted universe multiverse
deb http://security.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
deb http://extras.ubuntu.com/ubuntu trusty main
deb http://archive.canonical.com/ubuntu/ trusty partner
deb http://repos.azulsystems.com/ubuntu stable main
deb http://dl.google.com/linux/chrome/deb/ stable main
deb http://dl.google.com/linux/chrome-remote-desktop/deb/ stable main
deb http://linux.dropbox.com/ubuntu trusty main
deb http://downloads.hipchat.com/linux/apt stable main
deb http://repository.spotify.com stable non-free
deb http://archive.getdeb.net/ubuntu trusty-getdeb apps games
deb https://get.docker.io/ubuntu docker main
deb http://debian.sur5r.net/i3/ trusty universe
deb http://winswitch.org/ trusty main
deb http://debrepos.franzoni.eu/atom squeeze main
deb http://ppa.launchpad.net/webupd8team/sublime-text-3/ubuntu trusty main
deb http://ppa.launchpad.net/git-core/ppa/ubuntu trusty main
deb http://ppa.launchpad.net/nowrep/qupzilla/ubuntu trusty main
deb http://ppa.launchpad.net/noobslab/indicators/ubuntu trusty main
deb http://ppa.launchpad.net/mc3man/trusty-media/ubuntu trusty main
deb http://ppa.launchpad.net/hugegreenbug/cmt2/ubuntu trusty main
deb http://ppa.launchpad.net/modriscoll/nzbget/ubuntu trusty main
First apt-get update
apt-get update will complain about missing keys. To import them, use something like:
You should be verifying those PGP keys. [insert thought-through security blah blah everybody will ignore]
Configure the X session
As i3 maps quite a lot under its modifier, I use Mod4 (presented by i3 as “win” during the configuration assistant) but make it Right Alt instead of the Search key to avoid any conflicts. Sorry to users of non-US keyboards.
URxvt*foreground: white
URxvt*background: black
URxvt*cursorColor: red
Running VPNs
Make sure the resolvconf package isn’t installed so /etc/hosts will be correctly written, both in the crouton chroot and on the host (as crouton ties them together).
TUN devices get automatically destroyed by the network manager, shill, which will break OpenConnect, vpnc and OpenVPN. To disable this behaviour until the next boot:
I kept most of my personal configuration out of this document, but I’d be happy to explore more in future posts. Let me know what you’d like to see covered on Twitter!
If accesses are frequent and non-linear, performance remains reasonable as long as they are cached in memory. Then suddenly, some background job is triggered, a backup for example, and the data gets evicted from the page cache. Performance drops.
In many cases this is acceptable. The service throughput drops. In a request-reply model, requests get queued. But if latency is not critical, remains below the client timeout, and if the machine is dimensioned properly, data will be cached again, the service will catch up. The temporary slowdown was acceptable.
In other cases, this is catastrophic. Think high-frequency trading.
Here comes pcmad, the “Page Cache My Assets” daemon. It simply locks and unlocks files in memory as requested. When a file is locked, it won’t be evicted, whatever happens on the server. If the system runs out of memory, the oom-killer would be likely to kill this daemon first, so the upstart job and systemd unit indicate that killing pcmad should be avoided at all costs.
A simple and documented protocol, based on ØMQ and MessagePack, makes pcma easy to integrate with your existing services. For scripts, we also ship a client.
The project reached 0.2.0. It isn’t stabilized yet, so the protocol might not remain backward-compatible. However the code is simple and passed reviews, so feel free to give it a go!
On fedoraproject.org, the new prominent installation media with Fedora 15 is the live desktop, eg. Fedora-15-x86_64-Live-Desktop.iso.
Download it, boot it in VirtualBox. Gnome 3 will use the fallback mode. How do you start the installer? Well, turns out it is normally made prominent by a Gnome Shell extension (~/.local/share/gnome-shell/extensions/Installer@shell-extensions.fedoraproject.org/).
Did I mention that in fallback mode, which you can enjoy with most virtualization technologies, Gnome Shell is not running? Instead the installer ends up in the menu. Somehow it took me over 15 minutes to find it. Most people would be ashamed, I blog about it.
In case you wonder how to start the Fedora 15 installer in your virtual machine (SEO)… You can find it in Applications → System Tools → Install to Hard Drive. Alternatively, Alt+F2, liveinst. My bad for not partaking in the testing effort…
It makes me feel old and nerdy, but I love console-based installation processes.
I wanted a minimal, fullscreen clock I could run without X. In the longer term, I am thinking about a locking console “screensaver”; (more about that later). I ended up writing a small library (240 lines and counting) to render a 7-segment display in monospaced text at any “resolution”.
The end result adapts to the console size, instantaneously if resized. It lacks any options, if I'm bored again I might come back to it. It should be quite efficient, though more trivial optimizations are possible.
Older screenshots from various prototypes (the test program is available alongside the clock; as usual, I recommend sticking to the instructions in INSTALL at the root of the repo):
As a Technical Support Engineer at Red Hat, I got to read a lot of logs, error messages and code. One of my pain points was errnos.
They rely on magic numbers, which is perfectly understandable given their use cases (eg return values for system calls). But obviously, we're not going to be using magic numbers everywhere, hence they are defined as constants for the C preprocessor.
Numbers are not very user-friendly, so why not display them in a human-readable format when a human might want to read it? strerror comes to the rescue! Unfortunately, not every piece of code presenting errors to the user or administrator uses it. There are various reasons for that:
It is a libc function, and the Linux kernel didn't implement something similar (or most of us aren't aware of its existence);
The length of the (hexa)decimal representation of an integer is bound, whereas the strings it returns are not, which can make memory allocation for log messages trickier.
strerror strings are very readable; for example, it will turn ENOMEM into Cannot allocate memory under OSX. I will not lose too much of your time on the annoyances caused by weird usages of errnos, though I encountered quite a few already: they usually do not delay troubleshooting too much if you're not too trusting. For example ENOTDIR, represented by glibc's strerror as Not a directory, indicates when returned by keyctl_search(3) that one of the keyrings is a valid key that isn't a keyring.
The tricky part now? From a number or an strerror description in logs or an output, there is no trivial way to establish which constant to look for. What's more, C preprocessor constants are not available at runtime, you'd need the headers at hand, cpp, and your own list to go through as there isn't a standard one! For example, if you see 44, 0x2c or Channel number out of range, what should you git grep for in the affected software, libc and/or kernel? ECHRNG, of course!
I'd love to give you a simple table listing each errno constant, its representation in decimal and hexadecimal and its strerror description, but there are a few reasons why I can't:
Probably mostly for historical reasons, the association between constants and integer values is not common between operating systems; worse, they can also change between hardware architectures.
The strerror representation varies between systems, in particular depending on the libc being used.
Some operating systems use the same value for multiple constants. This is not a bug per se as long as no standard function can return those different constants for different reasons. On my systems, those are EDEADLK and EDEADLOCK under Linux, EAGAIN and EWOULDBLOCK under OSX.
However, this led to the creation of a simple command-line utility, errnos. Build and run it on the system you investigate, or a similar one (same operating system, same libc, same CPU architecture), and you will get something you can store and grep at will. It could also make an ironic wallpaper for your child's room, but don't blame me if they have nightmares of production systems going down.
For once, I used glib as I needed a hashtable of lists and couldn't be bothered implementing those for the millionth time in history (comp. sci. students who have to do so tonight, I share your frustration). There's a limited amount of magic involved in the build process, so please just clone the repository and stick to the build instructions unless you have time to lose.
The first column gives the number in its decimal representation, the second in hexadecimal. The third is either its strerror representation between double quotes or a preprocessor constant.
To close this post, here is the end of its output on my Mac:
$ errnos |tail
Stopped looking at 112899 0x63 "Not a STREAM"99 0x63 ENOSTR
100 0x64 "Protocol error"100 0x64 EPROTO
101 0x65 "STREAM ioctl timeout"101 0x65 ETIME
102 0x66 "Operation not supported on socket"102 0x66 EOPNOTSUPP
103 0x67 "Policy not found"103 0x67 ENOPOLICY
When you end up having to dictate Unix commands over the phone, you quickly learn from your colleagues that optimism doesn’t compensate your French accent. Turns out cancelling your lovefilm subscription triggers a similar problem.
The most common answer is to involve the NATO phonetic alphabet. Looking up a table pinned to your desk is tedious, getting fluent takes time. That’s where nato kicks in.X
After this very useful piece of software (at least to some), let’s have a look at something stupid and useless (I won’t even bother trying to explain the silly reason I needed it). If you ever have a good, real-life reason to run superglob, please E-mail me right away, I’ll owe you the drink of your choice. The idea is to build a glob matching all the arguments provided, but as little more as possible (and we’re far from being clever here).
You want passwords that are identical with AZERTY, QWERTY and QWERTZ keyboards? And easier to type on a mobile phone (no uppercase)? Alternatively, with the characters you list and just those?
You don’t want to choose a number of characters, how many digits and special characters should appear (or any nonsensical policy when you know what you are doing), but rather would rely solely on the number of bits of entropy you’ll get?
Generated from /dev/random, as it’s a good source of entropy (under a recent Linux kernel at least).































































































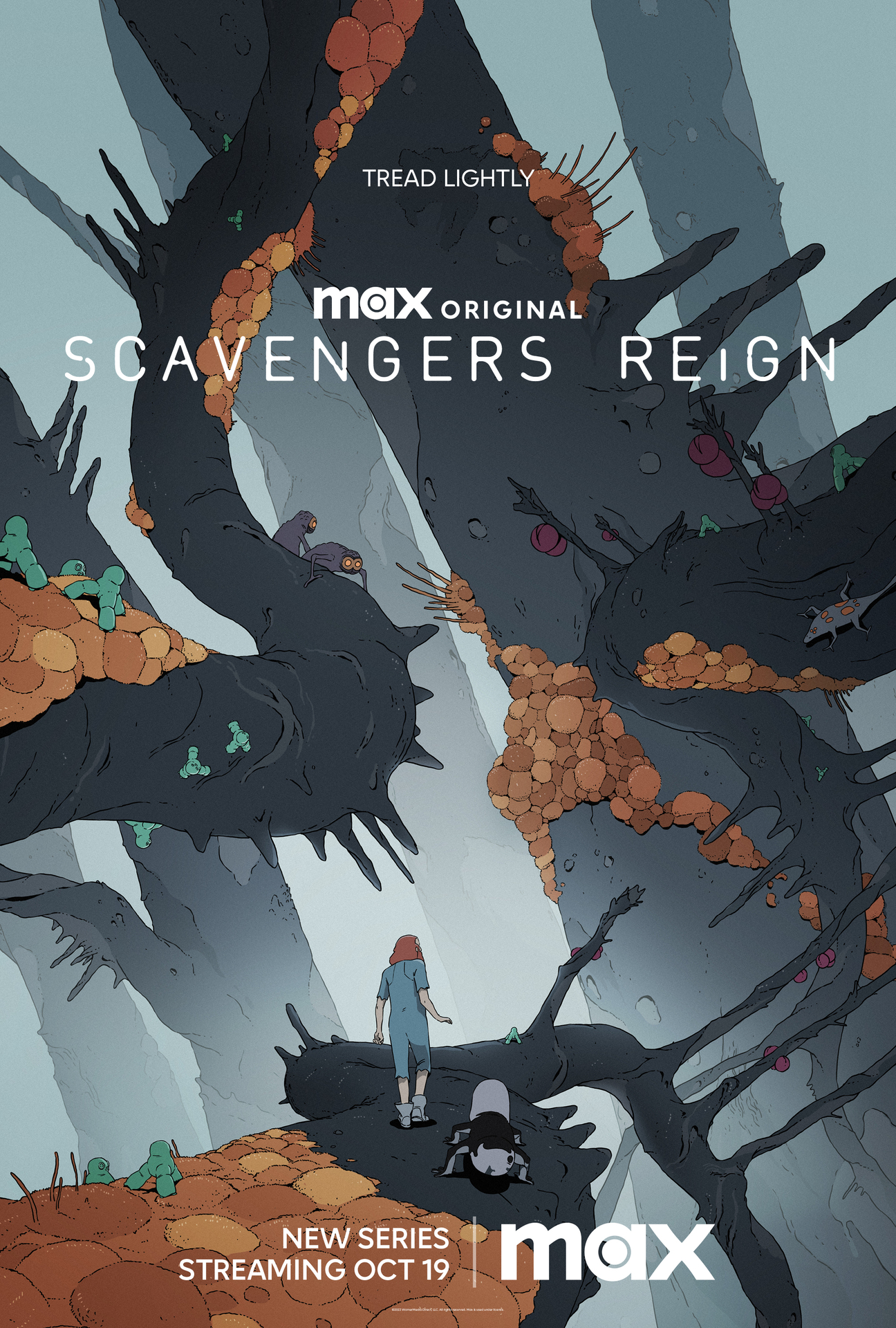













{kind=link}